We are living through an AI revolution that shows no signs of slowing down. I mean, every day when you scroll the internet, you come across a new term. I know it can get overwhelming and can lead to a feeling of being left behind. So, to get things started, the goal of this article is to help you catch up on the essential knowledge required in this age without feeling overwhelmed. Strong foundational roots make it much easier to catch up on new advancements. That is exactly what we are doing here. I will break down a few must-know AI concepts in a way that's easy for you to grasp. Learning these will give you the confidence to move far past the beginner stage.
1. Transformer Architecture & Self-Attention
In 2017, a team of researchers at Google published a paper that changed everything. A paper titled "Attention Is All You Need" introduced the Transformer architecture. Before Transformers, we relied on Recurrent Neural Networks (RNNs) to process text. RNNs read words in a sequential manner. This means they looked at one word after the other. And that's where the problem began. This sequential reading made training extremely slow. This also meant that by the time the model reached the end of a long sentence, it often forgot information from the beginning.
Thanks to Transformers, this fundamental flaw has been fixed. The biggest advantage of Transformers is that they can process all the words in a sentence at the same time. They do this using a mechanism called self-attention.
Self-attention is a mechanism in which every word in a sentence looks at every other word and decides which ones are most important. For example, in the phrase "the bank of the river," the model recognizes that the word "bank" is closely related to "river". This helps the model understand that the sentence refers to the side of a river, not to a financial institution, also known as a bank.
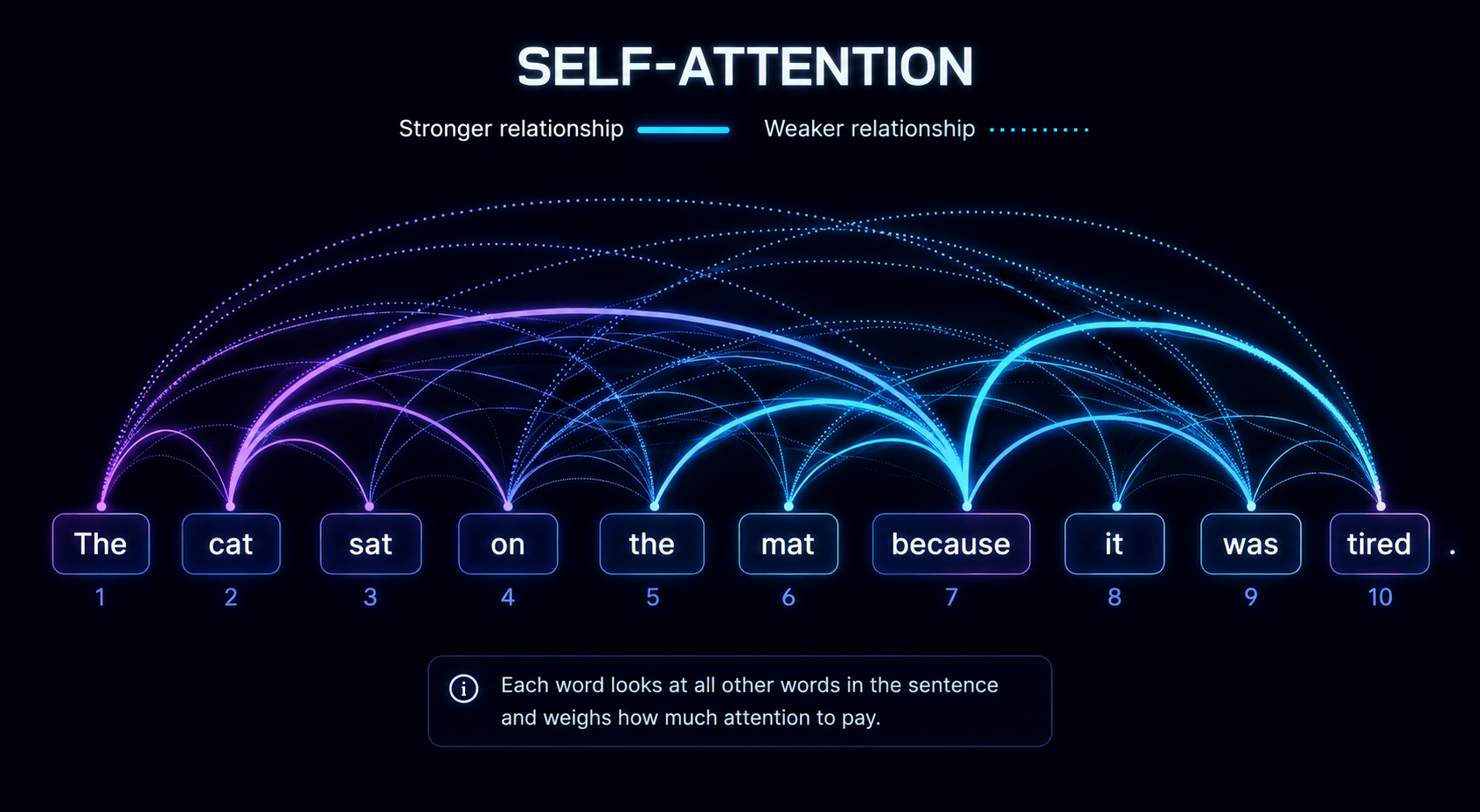
Now that you know Transformers read everything at once, they need a way to understand the order of words in a sentence. So, this gets handled through positional encoding. Positional encoding is a technique that provides each word with information about its position in a sentence.
Because Transformers no longer have to process words one after another, they can handle entire sequences in parallel. This made it possible to train models across thousands of GPUs simultaneously. This powerful improvement is one of the main reasons behind today's massive AI models.
Now that you've understood Transformer, let's proceed with one of the most talked-about AI concepts.
2. Large Language Models (LLMs)
If the Transformer is the engine, then a Large Language Model (LLM) is the complete vehicle built around it. LLMs use the Transformer architecture and scale it up by training on enormous amounts of text. This text is scraped from the internet.
The famous GPT-3 paper, Language Models are Few-Shot Learners, showed that increasing the size of these models can unlock new capabilities. Despite all the impressive abilities that LLMs have, they perform one fundamental task: predicting the next token.
A token is just a piece of a word. When you ask an LLM a question, it's not thinking about the answer the way you and I do. Instead, it looks at the tokens in your prompt. It then calculates the mathematical probability of the next logical token. Then it predicts the next one. And the next one.
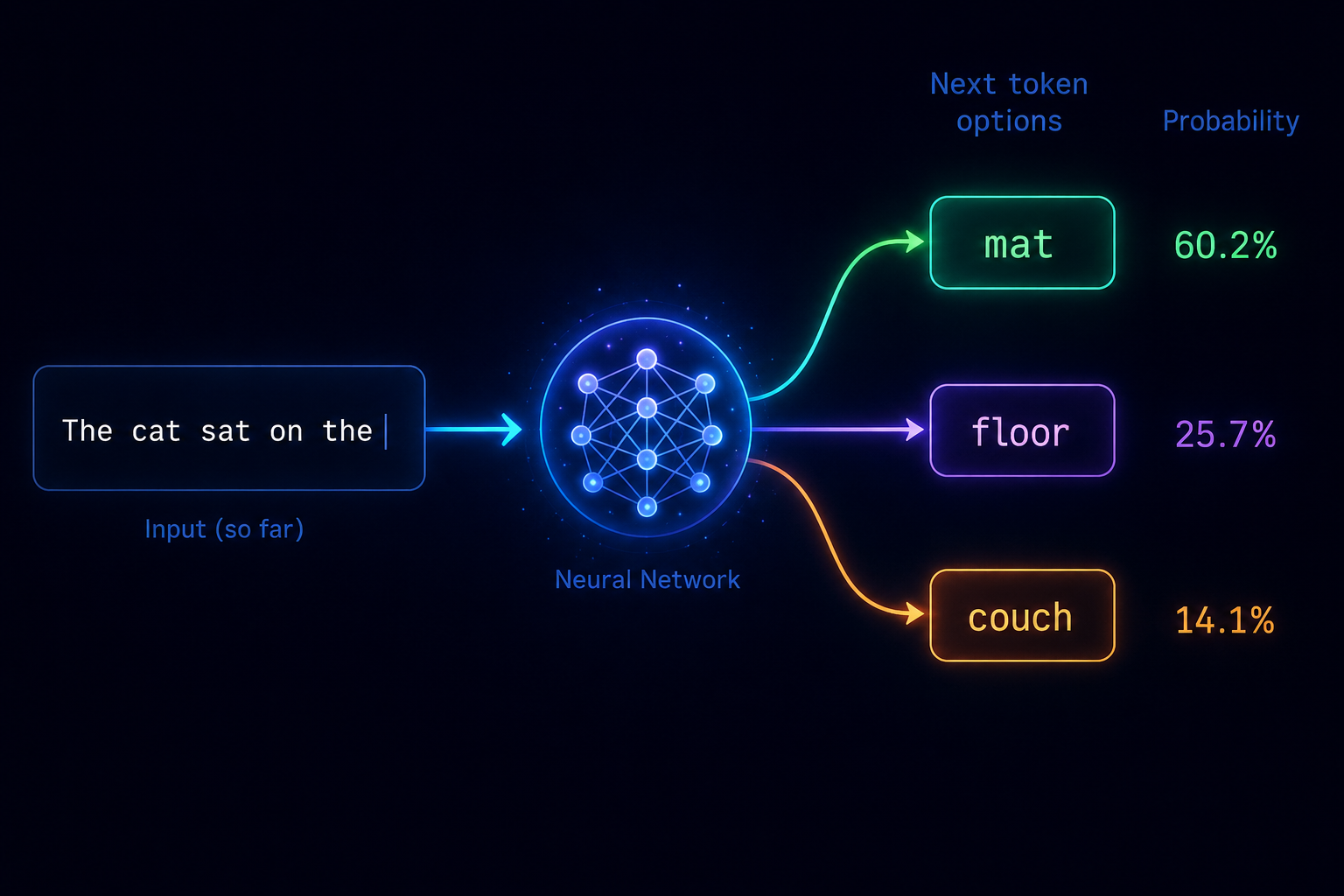
This process sounds surprisingly simple. However, at a scale of billions of parameters, the model starts to get better at prediction. It begins to capture the underlying logic, grammar, and reasoning patterns of human language. I would say LLMs are pattern-matching systems at an extreme level.
Despite all their strengths, LLMs do have some limitations. For example, you may not always have access to the exact model you want because you're restricted by the models supported by your IDE or platform.
Another major limitation is that LLMs have a fixed knowledge base. Once training is complete, they do not automatically learn new information. As a result, if you ask the LLM about a very recent event, it may confidently give an incorrect answer if it hasn't yet observed it.
We can't just rely on what they have learned during training. To make these models truly useful in real-world applications, we need a way to provide them with up-to-date, dynamic information.
3. Vector Databases & Embeddings
To solve the problem of a fixed knowledge base, we first need a way for machines to understand our private data. This is where embeddings and vector databases come in.
These language models don't understand text the way we humans do. This is because they work with numbers. An embedding model converts a piece of text into a list of numbers called a vector. These vectors capture the meaning of the text in a mathematical space. Because of this, concepts having similar meanings end up close to one another. For example, the vectors for "dog" and "puppy" will be very close, even though the two words are spelled differently. It's all about similarity in terms of meaning.
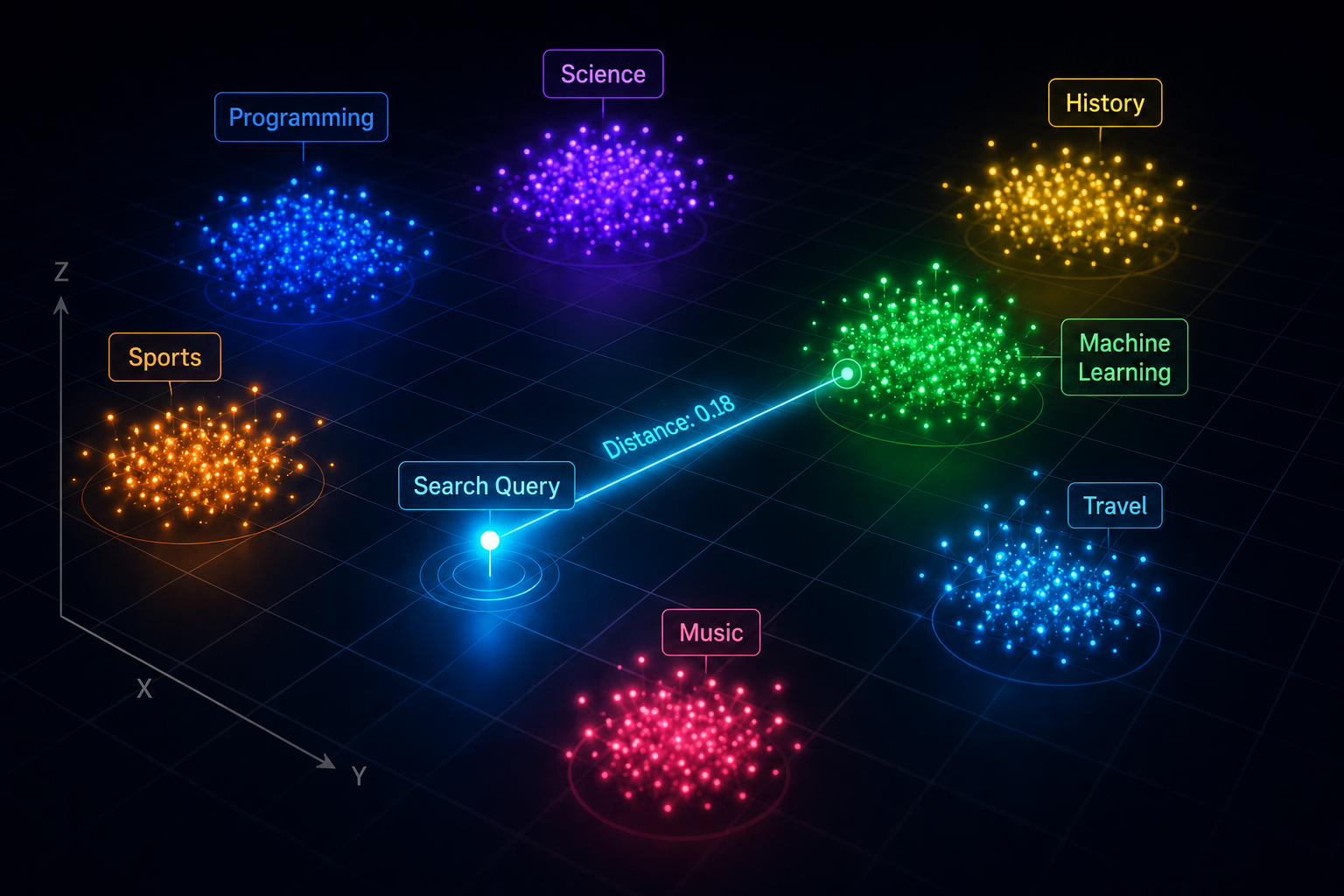
Once our documents have been converted to vectors, we need a place to store them. That's where vector databases come into play. A few popular ones are Pinecone, Qdrant, and Chroma. These databases are not like traditional SQL databases. Here we do not search for exact keywords. The goal of vector databases is to perform similarity searches.
When a user asks a question, that question is also converted into a vector. The database then compares it with the vectors of all stored documents and finds the ones that are closest in meaning. This helps AI systems search through millions of documents based on context and semantics, rather than exact word matches. This eventually results in much more accurate retrieval.
4. Retrieval-Augmented Generation (RAG)
Now let's combine LLMs with vector databases to create a system called Retrieval-Augmented Generation (RAG). It got introduced in a landmark 2020 paper. Since then, RAG immediately gained attention. It quickly became one of the most popular architectures for building enterprise AI applications.
The simple idea behind RAG is that, instead of relying solely on the model's training data, we give it access to your own documents and knowledge base. This helps reduce the number of models that give incorrect answers. This is because it allows the model to answer questions using verified information.
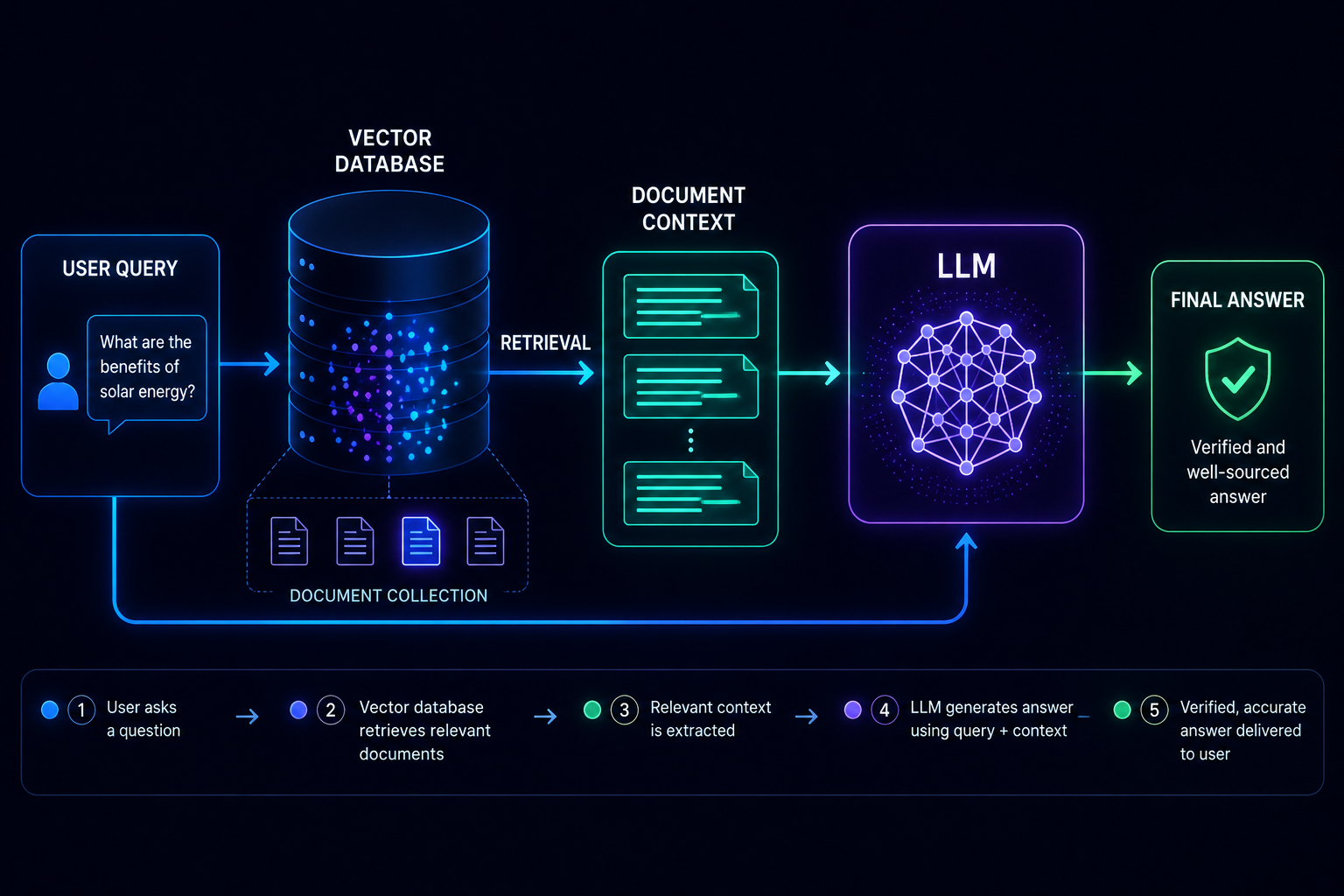
The entire process happens behind the scenes in just a few milliseconds. When a user asks a question, the query is first converted into a vector. The vector database then searches for the most relevant information and retrieves it from your documents. These retrieved passages are combined with the user's original question and sent to the LLM.
This is like giving the model an open-book exam. The model is no longer completely dependent on its fixed training knowledge. Now it can read the exact information needed to answer the question.
In production systems, retrieval quality is extremely important. If irrelevant documents are retrieved, the model will produce poor answers. That's why engineers carefully tune similarity thresholds and retrieval logic to ensure that only the most relevant information is passed to the model.
RAG has the ability to transform a general-purpose chatbot into a domain expert that understands your company's specific knowledge and documents.
5. AI Agents & Agentic Workflows
Generating text is great, but the real goal has always been to build systems that can take action. And that's exactly where AI agents come in. An AI agent uses an LLM as its reasoning engine. Instead of simply answering questions, it can plan tasks, make decisions, use available tools to take action, and execute multiple steps to achieve a goal.
The issue with traditional applications was that they relied on hard-coded logic. Logic such as if X happens, do Y. Agentic systems work differently. You provide the agent with a goal and a set of tools, and it determines the steps needed to complete the task. This idea became popular through frameworks like ReAct, which combine reasoning with action.
For example, suppose you ask an agent to summarize a YouTube video. The agent might first use a transcription tool to retrieve the captions and then generate the summary. If the tool fails because of an API change, a well-designed agent can recognize the failure, adjust its approach, and try again. This ability to learn from errors and recover is known as a reflection loop.
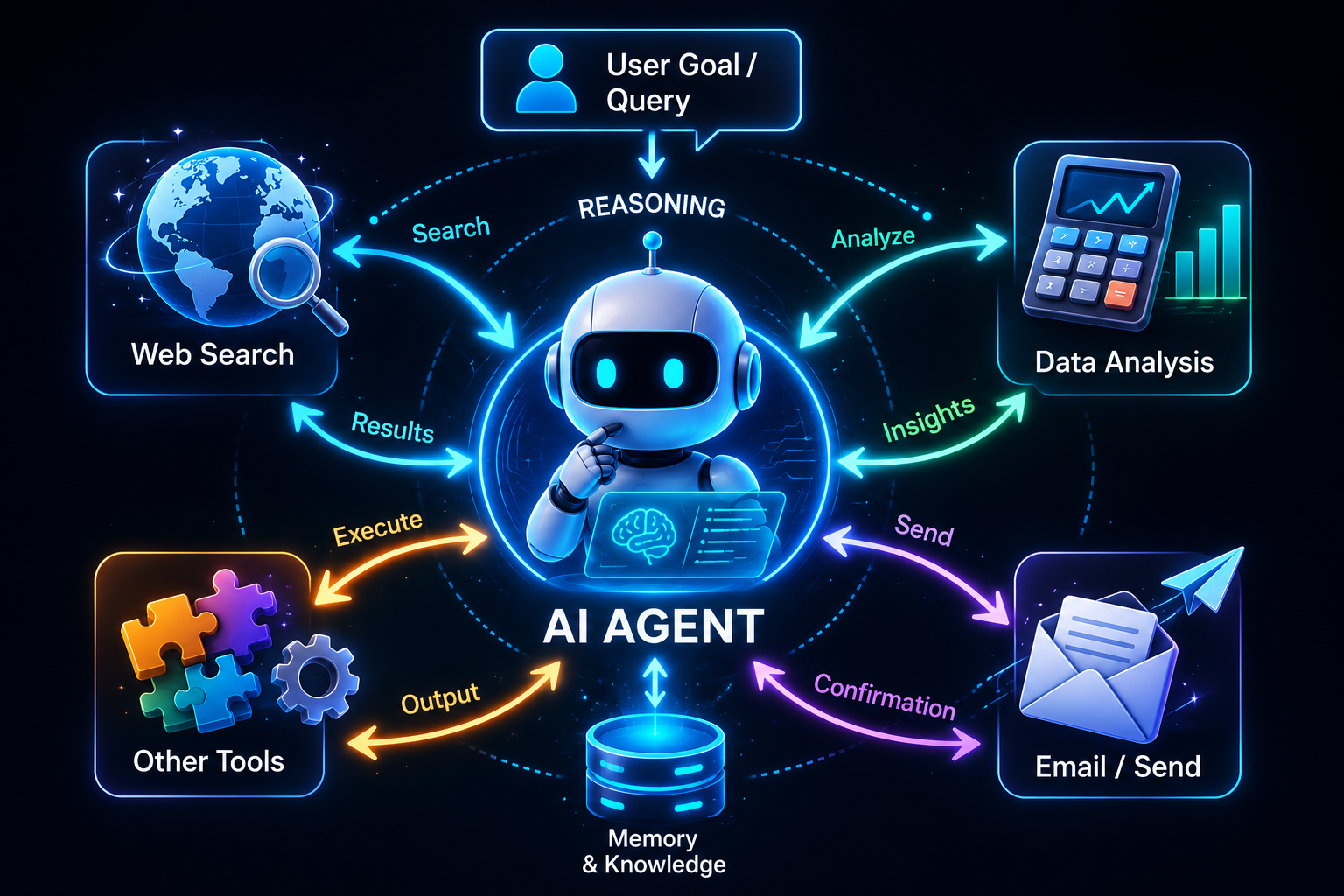
Agents are changing AI into an active digital worker, and honestly, that's what the future looks like. They can search the web for recent information, analyze data, call external APIs, send emails, and update databases. However, building these systems introduces a new challenge. The challenge is in securely connecting and managing all of these external tools.
As AI systems become more capable, tool integration and orchestration are emerging as some of the biggest engineering challenges to solve.
6. The Model Context Protocol (MCP)
We just saw that AI agents need tools to be truly useful. But connecting models to external tools has traditionally been a messy process. What I mean is that if you wanted your agent to read a GitHub repository, query a PostgreSQL database, and send messages to Slack, you had to build separate integrations for each.
To solve this problem, Anthropic introduced the Model Context Protocol (MCP), an open standard for connecting AI applications to external tools and data sources.
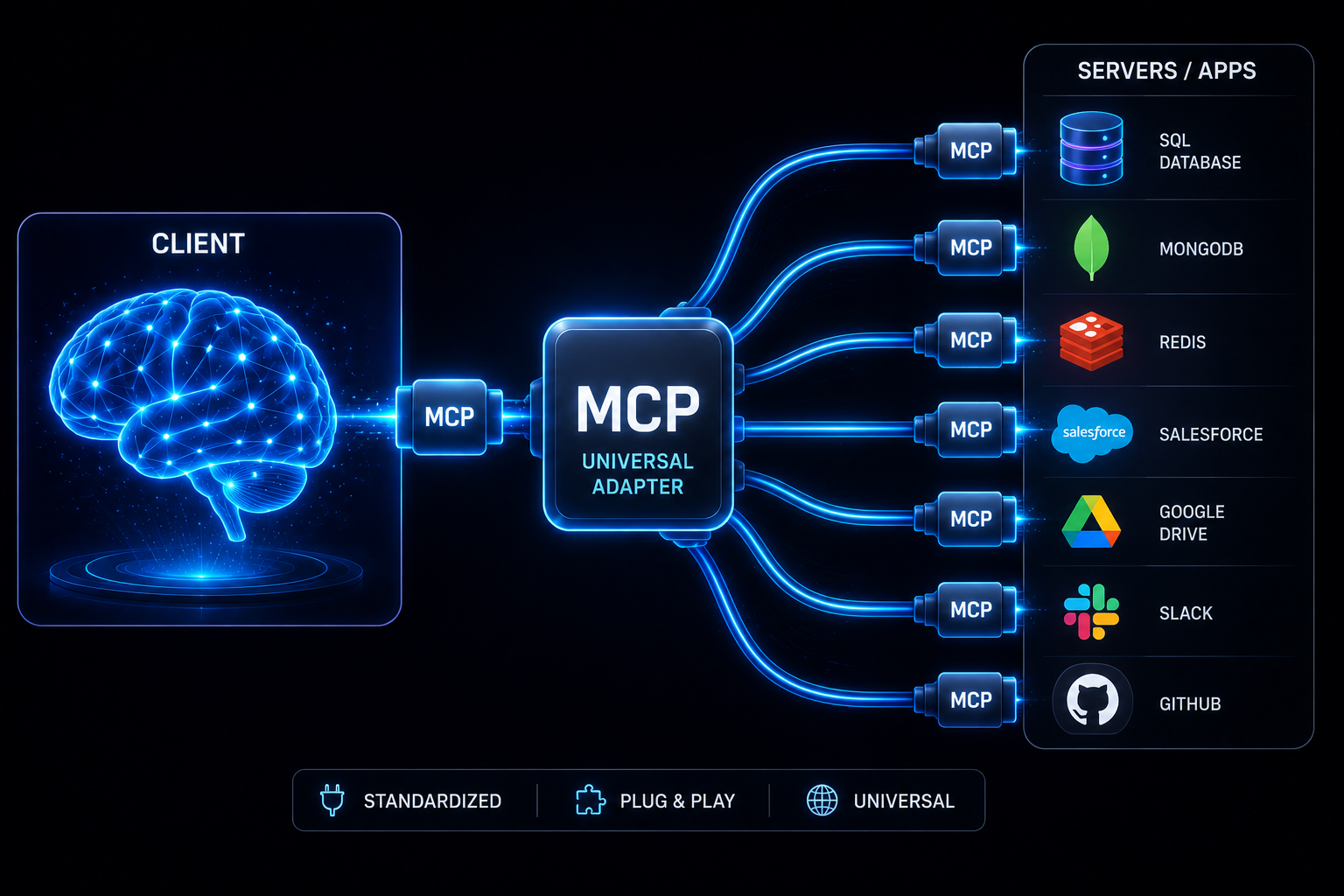
A very easy way to think about MCP is to think of it as the USB-C of AI. Before USB-C, every device needed its own charger. Similarly, before MCP, every tool required its own custom integration. MCP provides a common language that allows AI applications and tools to communicate in a standardized way.
In this architecture, the external tool runs as an MCP server. The server exposes the tool's capabilities through a standard interface. Our AI agent acts as the MCP client. Since both sides are following the same protocol, the agent automatically knows how to interact with the tool without any custom integration.
This makes AI development much faster. The best part is that you no longer need to build every connection from scratch. Developers can simply plug existing MCP servers into their agentic workflows. As a result, AI models can securely access databases, repositories, messaging platforms, and other available tools through a common standard.
Conclusion
The evolution from simple chatbots to autonomous AI systems has completely changed the landscape of software engineering. We started with the Transformer architecture and saw how it gave rise to Large Language Models. We then explored how vector databases and RAG help in providing reliable knowledge. Finally, we looked at how AI agents and the Model Context Protocol (MCP) allow models to interact with external tools and perform actions.
These are the most important concepts that anyone interested should be aware of. Understanding them will help you build more capable AI applications.
Frequently Asked Questions
1. What is the difference between a Transformer and an LLM?
A Transformer is the neural network architecture that introduced self-attention. It made modern language models possible. A Large Language Model (LLM) is built on top of this architecture and trained on massive amounts of text to predict tokens and generate responses.
2. What is the difference between RAG and fine-tuning?
RAG (Retrieval-Augmented Generation) provides an LLM with access to external data sources. This helps the LLMs to retrieve up-to-date information when answering questions. Fine-tuning, on the other hand, changes the model's internal weights by training it on a specific dataset. In general, use RAG to provide new, updated knowledge and fine-tuning to change the model's behavior or style.
3. Why do we need vector databases?
Vector databases store embeddings, which are numerical representations of text. They help AI systems to search by meaning rather than exact keywords. This is what makes them an essential component of modern RAG systems.
4. What is the Model Context Protocol (MCP)?
The Model Context Protocol (MCP) is an open standard that provides a common way for AI applications to interact with external tools and data sources. So you don't need to build separate integrations for every service. Developers can use MCP to connect models to databases, repositories, messaging platforms, and other tools through a standardized interface.